
Aug 16, 2024
Share with friend:
What is OCR (Optical Character Recognition)?
Optical Character Recognition, commonly referred to as OCR is a technology that allows computer programs to detect and extract text from images and scanned documents.
Besides extracting textual information, it also enables the conversion of one format of documents to another and physical ones into digital ones.
How OCR Works
OCR works by detecting characters and letters present inside an image or scanned document and then converting them into machine-readable data. However, this is a pretty general description of the process.
For your better understanding, we’re going to dig deep into the workings of this technology below. It works mainly in four steps and they are:
1. Image Acquisition
The first step in OCR is acquiring the image or document from which the text has to be extracted. This can be done using a scanner, camera, or any other device that is capable of capturing digital photos of a printed page.
Usually, image acquisition is not something that OCR tools do themselves, instead, users have to provide them. They have to upload images or documents that they want to perform extraction on.
2. Preprocessing
Once an OCR tool acquires the image, it begins the next step, which is preprocessing. Before the text can be recognized, the tool has to process the image to enhance its quality. This involves several tasks such as:
- Noise Reduction: Here, the OCR tool or software removes unwanted noise from the acquired image. This enables it to better scan the text present since there won’t be any obstacles.
- Binarization: To better distinguish between the text and the background, OCR converts the image to black and white. This simplifies the recognition process and improves accuracy.
- Orientation Adjustment: OCR tools work best when they scan images in a portrait orientation. This is because the text is aligned properly this way. Here, the tilt in images is fixed and they are adjusted to the tool’s liking.
Having said that, the great thing about OCR is that it can perform all the aforementioned tasks simultaneously on a picture. However, when needed, it can perform them one by one, resulting in a delayed but often more accurate output.
3. Character Recognition
Once the image is processed by OCR, it begins the next phase, which is character recognition. Here, the technology identifies the individual characters, words, and sentences. Basically, in this step, the extraction process begins.
Character recognition is usually done in two ways and those are:
- Feature Extraction: It involves identifying the distinct attributes or patterns of a character. Obviously, each character doesn’t have the same features, so these things are used to differentiate between them by OCR. These attributes might include lines, curves, edges, corners, and other structural elements.
- Template Matching: This is a simpler method of character recognition. As the name suggests, in template matching, the OCR system scans the characters and compares them with predefined templates that are stored in the database.
Both these ways of character recognition are considered advanced and are being used in modern OCR systems. Depending on the acquired image, the software determines which method it is going to use.
4. Post-Processing
After the OCR system has recognized the characters present inside an image or scanned document, it moves on to this step. Here, the output is refined before providing the user.
Some of the processes that occur in post-processing are as follows:
- Cross Checking: The OCR tools check one last time whether they have extracted the exact text that was present in the image or document. If so, the output is shown to the user and if not, it is refined further. Additionally, grammar checks are also performed to make the output as accurate as possible.
- Formatting: Here, the extracted characters are checked to maintain their original formatting, just as they were in the image. They are bold, italicized, and underlined respectively. The alignment of the output is also kept the same as it was before.
This is the general process of how an OCR system works under the hood.
Applications of OCR
The technology has made its way into various industries and is currently being used to streamline processes and improve efficiency. Some of the most common applications of OCR in the modern world are as follows.
1. Document Digitization
One of the main uses of OCR is document digitization. All around the world, this technology is used to convert physical documents into digital formats so they can use less space and can be stored in a better way.
The searchability, management, and retrieval of digital documents becomes easier this way. For instance, libraries use OCR to digitize books and archives. This makes them accessible to a broader audience.
2. Automated Data Entry
Data entry tasks are mainly being automated using OCR technology. In the past, businesses used to hire data entry experts to process invoices, receipts, and forms, extracting relevant information from them.
However, this is not the case anymore as these things are done by OCR in an instant, removing the need for human intervention. This saves time and also reduces errors.
3. Paperwork Verification in Banks
The technology is often used in banks to digitize and verify the paperwork of customers for loan approval, deposit checks, and other transactional purposes.
This frees us employees and they can spend their time doing other productive tasks. All in all, the bank benefits greatly from using OCR.
4. Patient Record Processing in Hospitals
In healthcare, OCR is used to process the previous records of patients. These records include treatment, test results, and payment receipts, among other things. They are digitized and stored in the cloud network of the hospital.
This way, the hospital database is kept up to date and patients are treated with more insight. Doctors don’t have to ask their long-term patients about what medicines they’ve been taking in the past every time they visit.
5. Streamline Document Handling in Law Firms
For a place that’s heavily reliant on legal documents, OCR is great. Affidavits, judgments, filings, statements, wills, and other documents are digitized using the technology.
This enables lawyers to access them quickly when needed and the whole process of handling them is streamlined. Past cases can be looked into better this way as no one would have to go through multiple files.
Challenges and Limitations with OCR
While PCR technology streamlines various tasks and improves efficiency, it is not without its limitations. Some of the most prominent ones are mentioned below.
Occasional Accuracy Issues:
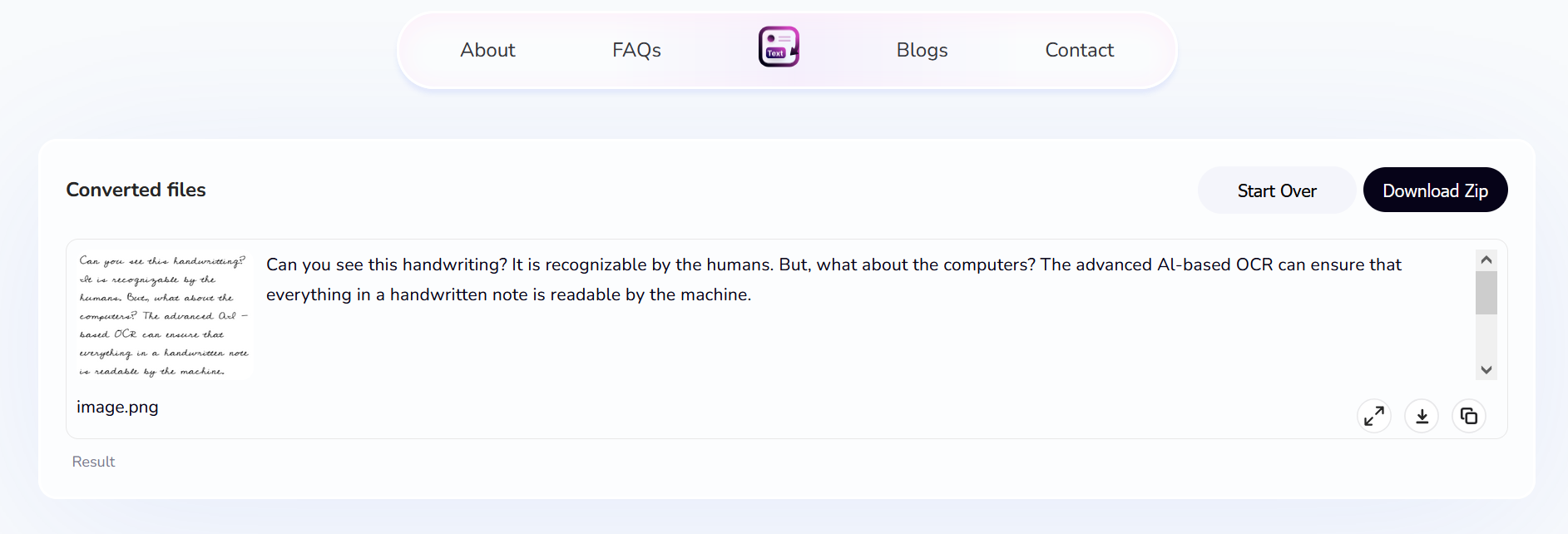
The accuracy of OCR systems can be impacted by multiple factors. Some of them include poor-quality scans, complex fonts, and bad handwriting.
However, modern OCR tools, ones that are paired with artificial intelligence like our Picture to Text Converter have eliminated this issue. It is good at detecting any type of handwriting and fonts.
To demonstrate, we’re going to use the following picture of handwritten text and see how well our tool can extract text from it.

Tool’s Output:
Language and Script Limitations
OCR systems and tools are generally optimized to work for certain languages and scripts. This is why, they may have difficulty in accurately extracting text in more than one or less common languages and scripts.
However, with our Picture to Text Converter, this isn’t a problem as it supports multiple languages and can extract text accurately in all of them.
Complex Layouts
Documents and images that contain complex text layouts such as tables, columns, or mixed content (text and images) can sometimes pose challenges for OCR systems. In some cases, manual correction may be required to ensure the accuracy of the extracted text.
While this issue mostly occurred back in the day, it isn’t that prominent now as tools, like our Picture to Text Converter, have gone through multiple updates to fix it.
Wrapping Up
Optical Character Recognition (OCR) is a technology that allows computers to extract text from images and scanned documents. It enables the conversion of physical documents into digital formats.
The process of OCR involves image acquisition, preprocessing, character recognition, and post-processing to refine the output.
OCR technology has various applications in industries such as document digitization, automated data entry, paperwork verification in banks, patient record processing in hospitals, and streamlining document handling in law firms.
While OCR systems may face challenges such as occasional accuracy issues, language and script limitations, and complex layouts, modern tools paired with artificial intelligence have significantly improved accuracy and efficiency in text extraction. All in all, OCR continues to enhance productivity and streamline processes across various sectors.


